How I Read Tens Of Thousands Of Emails In Seconds
A RAG experiment

As a long time professional in the hi-tech industry, I subscribed to many software development and other technical newsletters over the years. I get a lot of these tech/software related emails — which most of the times I don’t have time to read and they are just accumulating in my Outlook Dev folder.
When the old faithful Outlook begun to crack I knew I had to help it recover back to its youth. I thought I’ll delete some useless kept emails and free up some .pst memory (where Outlook saves its items) to help Outlook load faster and perform better. A quick scan of the Outlook items folders revealed tens of thousand of emails in the Dev folder — accumulated in the course of more than two decades of incoming newsletters. So I set up to delete those — but before I hit the “empty folder” command — I felt the nostalgic need to browse some of those emails. So I had a plan to browse them quickly before I delete them for good.
The naive approach
I thought I will quickly browse through the email content and then delete it. It was so naive. Soon I found myself down the rabbit hole of actually reading the email as it tue=rned out that many of them had interesting content. After a few of those I realised that this momentous task wil not be completed over my lifetime.
I had to find another way to extract some value from those emails, so I thought about LLM and RAG.
RAG
The new plan was to turn all those emails to a searchable repository of knowledge, and learn something new on the way.
I decided to use local LLM for this task.
I went straight into it. I already had installed before for educational purpose Ollama with llama3 and mistral language models. I decided to use it for my retrieval augmented generation (RAG) project.
Step 1 — Export Outlook Emails
I used pywin32 to interact with my Outlook (on a Windows machine).
Step 2 — Create The Textual Vault
Step 3 — Chat With My Emails
Now that we have vault.txt, we can use it with our local LLM tools.
I will not cover in this post how to install and use Ollama, the LLM models or Open UI. There are a lot of online guides for that. Check Chuck (no pun intended).
First we’ll use Open UI:
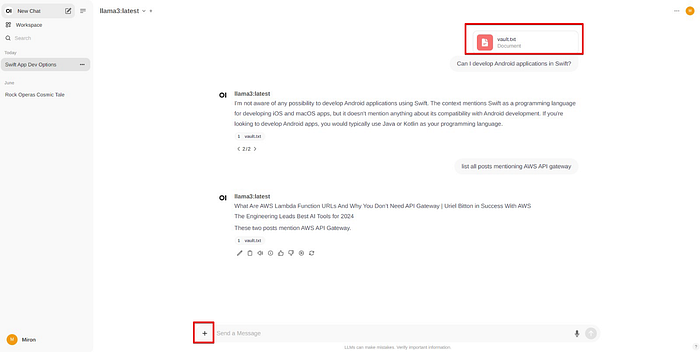
After adding the vault file to the LLM context, we can chat on topics specific to the content aggregated in the vault from all the emails.
For comparison, the same question without using the vault file:
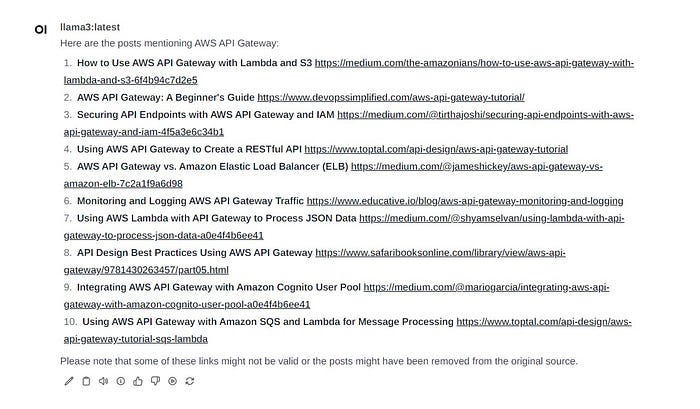
We can see links which we stripped when we processed the emails html content, so these results are from the llama3 model itself.
Same question with the context gives the expected response:
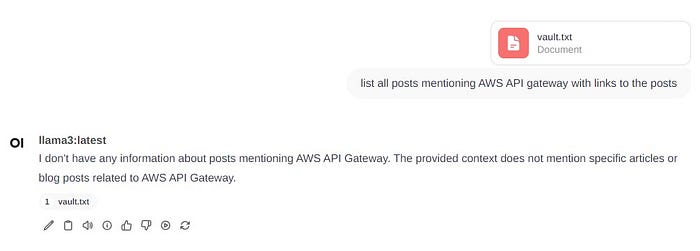
We will see later how we can improve this, with the emails HTML content.
We can also run it programmatically:
The response:
Based on the provided text, the following are the Medium posts related to Algorithmic Trading:
1. **I built a trading Algorithm that predicts the price of Bitcoin** by CyberPunkMetalHead (5 min read)
2. **Atomic Arbitrage: A Quantitative Study** by Open Crypto Trading Initiative (8 min read)Please note that these are the only two posts explicitly mentioning algorithmic trading in the provided text. There might be other related articles or topics discussed within the posts, but these two specifically focus on algorithmic trading.
In the next post we’ll use the emails HTML content and try to improve the RAG inference.
